



The world is becoming more connected every day. Where have you heard that before?
Enterprises, data analytics companies, data scientists … we’re all finding new ways to explore connections and relationships to see what they can tell us. It could be the search for better product recommendations for e-Commerce sites, banks searching for fraud indicators before it happens, or manufacturing companies looking for ways to improve the efficiency of their supply chains.
The most important aspect of any business process is understanding the relationships of any one action or asset as they relate to each other in that process.
Graph analysis recognizes that all data represents something in the real world, and almost everything in the real world is connected in some way. These relationships in data can tell us a lot. They can help us find new patterns and similarities (people like us – based on demographic, lifestyle, etc) and about how individuals are connected to form groups of like interests.
It might be applied to social media to enrich the customer view with patterns and relationships or well beyond commercial social analysis to detect patterns in otherwise innocuous communications that might indicate an imminent attack, market failure, or social upheaval. They can reveal what products we will likely purchase in a given scenario. Or they can predict how changes in one part of the organization or infrastructure can affect other parts.
What Is a Graph Database?
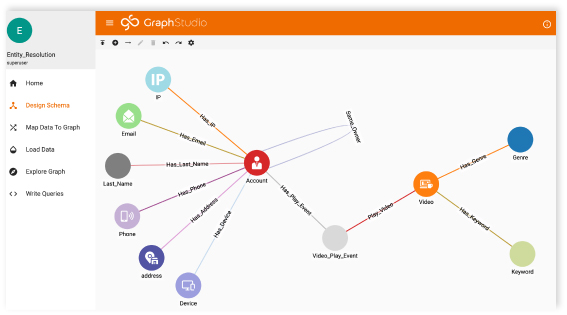
Graphs can be used to analyze all sorts of relationships across all kinds of systems — even beyond process or beyond the confines of individual operational models. Most common business questions require an understanding of the relationships between actors or objects. Graph databases and graph analytics were created out of this need to understand relationships in data. Graph databases feature the only data model where relationships between pieces of data are pre-connected. Graph analytics offers a simple way to analyze these relationships, revealing more about entities like people, products, accounts, and locations using SQL-like queries that don’t require programming experts to build or maintain them.
According to Gartner’s Afraz Jaffri at the 2022 Graph + AI Summit, “By 2025, context-driven analytics and AI models will replace 60% of existing models built on traditional data.” This is just one of many indications that graph technology will continue to grow more central to everyday business operations.
You Use Graphs Every Day
You probably didn’t realize that, but it’s true. Every time you search the internet using Google, you are using Google’s Knowledge Graph. Google is constantly refining the way it returns results for users’ searches, but one thing remains true. Every search is ranked using a graph algorithm called PageRank.
Consider what happens every time you log in to LinkedIn. When you search and view your professional contacts, you’ll see recommended contacts and the activity of people you are either directly or indirectly connected with. These relationships are displayed as 1st, 2nd, and 3rd-degree connections. This is the result of a graph database search on LinkedIn’s Professional Network Graph indicating the number of hops from you to the contact being reviewed. Every time you see common connections or common groups with a second-degree contact, or LinkedIn recommends you connect with a professional contact, you are querying the professional network graph at LinkedIn.
Let’s not forget about your retail and e-Commerce shopping experiences. Every time you use an online store, like Amazon, Wayfair, and many others, you likely now expect these services to provide product recommendations. They are represented by suggestions like “people who bought this item also bought…” or “these items are often bought together…”. That comes from a graph analytics query!
Traditional or legacy technologies like relational or NoSQL databases can’t store and analyze the relationship data to make these features a reality. Only graph databases can.
Challenges Using Relational or NoSQL Databases for Storing and Analyzing Relationships
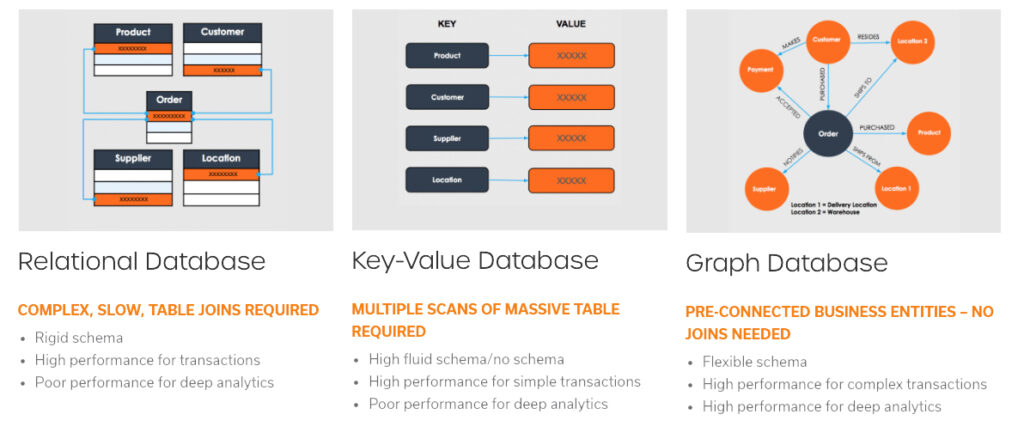
Relational databases store business facts in separate database tables. To reveal, analyze, and understand the relationships across these tables, housing information like customer details, order information, and product and payment data, you need to perform table joins in this setup. This process can take weeks and requires significant SQL programming even to build a query.
NoSQL databases were created in an attempt to resolve this problem by storing all data in a single table for fast retrieval, not designed for analysis.
Graph databases are purpose-built for storing and analyzing relationships among the data, as the data entities and relationships among them are pre-connected. This removes the need to perform time-consuming table joins and multiple scans across a large table. Using the power of relationships and context, graph techniques bring increasing accuracy, robustness, and versatility to predictive models and are incorporating graph analytics, graph-based features, and graph machine learning in their workflow to develop new AI applications.
With these obvious advantages in mind, you might ask yourself, “Why have enterprises not adopted graph databases faster?” It’s a valid question that requires a little history behind the development of graph technology.
Graph Database Adoption at the Enterprise Level
First-generation graph databases were built with native graph storage. They couldn’t, however, handle large data or query volumes or perform beyond three levels or connections inside the graph. They were excellent for visualizing relationships among business entities as an academic proof of concept. The scale simply wasn’t there initially for real-world enterprise production requirements. These early iterations were built on Java and were primarily designed for research and development, not the rigors of handling production use cases at scale.
Second-generation graph databases were built on top of NoSQL storage, which allowed them to load large amounts of data. However, they still didn’t scale for queries involving three or more connections or hops.
This limited their ability to perform deep or complex analysis. Modern graph platforms use C++ and are designed for enterprise use. The more modern approach allows for scaling compute power, mutability (meaning they support system updates), data streaming, and batching along with fast computation in the graph database, as opposed to outside the graph database and pulling the results into the database for the user to access.
Second-generation graph databases also typically didn’t support database sharding. This prevents organizations with terabytes of data from distributing the data onto multiple servers, each with a few hundred gigabytes of data.
Further demonstrating their limitations, first and second-generation graph databases:
- Can’t scale to multiple machines for storing big data (database sharding) and parallel query processing
- Can’t support deep link analytics (go beyond three hops) essential for next-generation fraud detection, recommendation engine, machine learning, and AI use cases
- Are unable to meet real-time requirements for updates and sub-second query performance on big data.
The promise inherent in graph databases and the shortcomings of previous generations led to developing a new generation in graph database and analytics technology. TigerGraph is part of that next generation, a native parallel graph database purpose-built for loading massive amounts of data (terabytes) in hours and analyzing as many as ten or more hops deep into relationships in real time. TigerGraph supports transactional as well as analytical workloads, is ACID compliant, and scales up and out with database sharding. TigerGraph’s open query language allows us to support modifications and explainable AI, delivering a platform that can be applied to multiple use cases and AI applications on connected data.
Companies around the world are investing in graph as a competitive advantage. Research in the field of graph algorithms and machine learning has shown that big improvements in predictive model quality can be made by structuring data in a graph structure that inherently captures context and relationships.
If you’re interested in experiencing graph for yourself, give TigerGraph a try for free. Our free license is available for both our on-premises and cloud products. Once you’ve gotten started, we encourage you to join the TigerGraph Community to continue your graph journey with support from both our team of experts and other TigerGraph users.




